
In my very first post ever I said that I would cover some technical topics that I found really interesting. But writing a technical blog is slightly more scary because there’s always that nagging doubt if you’ve understood it right and might end up misdirecting someone. So an earnest request if you find anything incorrect please point it out in the comments below and I’ll edit it.
Now that’s out of the way let’s crack on with the first edition of this new mini-series.
Data structures are the building blocks that are used to build most software. That’s why there is a lot of focus on it when you start studying Computer Science. Something that irks me is that, to most people, the end of Data Structures is using the CLRS Textbook to rinse and repeat during placement season and get a solid package. While that is all well and good, leveraging the properties of more complex data structures to suit your particular application to achieve an improvement in either time or space complexity is when you realize the true power of what you’ve learnt. One concept from a recent conversation with a friend really captivated my interest. That of the Merkle Tree.
A Merkle tree is basically a tree where each non-leaf node is given a value or label that is equivalent to the hash of its child nodes.
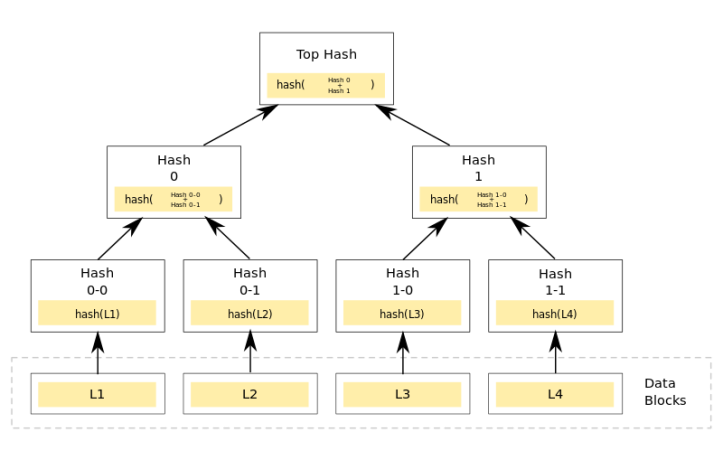
These are then used to calculate the labels of other nodes up until the Root of the tree. The label of the root node is called the Master Hash or Root Hash. A hash function can be used to construct the tree as long as it is kept uniform for the whole tree and it satisfies the following properties:
- For any given input it should give fixed size output,
- It should be deterministic i.e. for a given X, Hash(X) remains the same regardless of when you’ve computed it.
- For a given message x, it is hard to find y!=x such that Hash(y) = Hash(x) – Known as Second Preimage Resistance
- It should be easily computed
- You should not be able to guess X from Hash(X) – Preimage Resistance
The diagram above shows a Merkle Tree of branching factor 2, i.e. a Complete Binary Tree, but this can be increased as is required. The time complexity of Insert, Delete and Search Operations are all in O(Log(n)). This complexity is the same as that of a binary search tree. A hash function is chosen so that it can be computed quickly i.e. of constant time complexity or a few seconds for any given input. So on initializing the node you also perform the calculation of the hash from its children. Space required is O(n) again the same as that of BST.
The use case which caught my attention was that of data verification in Peer-To-Peer Systems. This is especially important with the growing acceptance of Blockchain based technologies. In Bitcoin for example, each leaf node represents a transaction and these are chained together in the form of blocks. Once a block is ready, the Merkle Tree for the same is created and the Master Hash is made public. If you see the leaf nodes of the tree in the diagram then you can see that they are labelled as Data Blocks, this is essentially what is happening to every block of transactions.
Bitcoin is a distributed P2P system so transactions need to be verified that they are coming from a valid peer. There are individuals called miners who perform the dual acts of creating the Merkle Trees and hence adding blocks to the block chain. Any other user can verify that the transactions completed by them are within a certain block and hence are completed so to speak. But it is inefficient to check the entirety of the block for this. This difficulty is overcome by using Merkle Trees.
Consider the tree below:
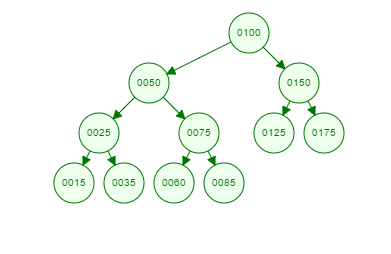
Suppose that A is a miner who has created the above tree and added the corresponding block to the blockchain. Now let us say that a user B has performed a transaction and that is represented by leaf node 15. If B wants to verify if this transaction was part of the block, he will now query A for the hashes of the sibling nodes on the path to the root alone. So B requests and receives Hash(35), Hash(75) and Hash(150). As opposed to requiring the hashes of every transaction in the block.
Using Hash(35) and the Hash(15), the Hash(25) can be determined. Combining Hash(75) with this result obtains Hash(50). Repeat again with Hash(150) to obtain the Master Hash and verify that it is the same. If they don’t match then you know that your transaction is not valid.
And now you only request one hash per layer of the tree and perform one such computation on each i.e. log(n) computations. This speedup can prove vital in situations like Bitcoin where the size of the Blockchain is enough for this improvement to prove invaluable.
One additional point to note is the requirement of the Second Preimage Resistance. Suppose that Hash(15) is the same as let’s say Hash(85). B could then be convinced that his transaction is present in the block if he is returned Hash(60), Hash(25) and Hash(150). This is obviously undesirable. Hence the requirement in the Hash function.
Also since only hashes are being sent across the network the process can proceed in a fast and secure manner.
With recently Japan, and many other countries in the past giving the green light to Bitcoin and other crypto-currencies like Ethereum on the rise (and we’re talking rising faster than the Undertaker Situp) you could be hearing more Merkle Trees in the future. And it’s not just confined to crypto currencies.
Merkle trees can be used to check for inconsistencies in more than just files and basic data structures like the blockchain. Apache Cassandra and other NoSQL systems use Merkle trees to detect inconsistencies between replicas of entire databases. Imagine a website that people use all over the world. That website probably needs databases and servers all over the world so that load times are good. If one of those databases gets altered, then every single other database needs to be altered in the same way. Hashes can be made of chunks of the databases, and Merkle trees can detect inconsistencies.
That was edition 1 then. Feedback welcome. 🙂

Bitcoin has experienced amazing growth over the last years and there will be those that are claiming that the bubble is about to end and Bitcoin crumble. Those of us continue support the concept of a user owned currency outside of the control of the banks. We will not believe that Bitcoin is finished. We shall be staying with Bitcoin and I am quite certain that Bitcoin will keep rising more steeply than in the past.
LikeLike